 2006, Vol. 32
2006, Vol. 32 近年来,随着多普勒雷达建设进度的加快,用雷达来探测冰雹己经成为比较重要的一种手段[1]。国外,Petrocchi最早提出了用一系列预报因子的权重来探测冰雹,给出了冰雹发生的三种可能性(POSITIVE/PROBABLE/NONE)该算法没有考虑环境温度,没有区分普通冰雹和大冰雹。效果不是很好。20世纪90年代,Johnson et. al提出了利用风暴定位(SCIT)来识别风暴单体,并在此基础上提出了冰雹探测的新算法[2]。该算法综合考虑了冰雹产生时风暴单体的反射率值,温度及高度的关系。得出了冰雹发生的三种产品(POH (冰雹概率/POSH(强冰雹概率)/MEHS (冰雹大小))国内,杨引明对上海引进的美国NEXTRAD的这套算法在业务上的应用进行了评价[3]。METSTAR公司生产的CINRAD-SA, SB都采用了基于美国NEX-TRAD的冰雹探测算法。但由于雷达软件版权的问题以及需要专门的显示软件,使得用户对产品的使用受到了一定的限制。本文作者详细分析了冰雹的算法,重新对算法进行了实现。通过一些有观测记录的冰雹实例对算法进行检验,并和METSTAR公司提供的新旧版本冰雹算法进行了比较。针对冰雹探测误报率过高的现象进行了算法改进尝试。
1 冰雹探测算法的主要步骤冰雹探测主要采用反射率因子的资料。首先使用风暴中心定位和追踪(SCIT)算法,定位三维风暴。然后利用垂直方向上风暴强度、高度和0℃/-20℃层的高度的关系,得出冰雹产生的概率以及强冰雹产生的概率,并对冰雹的大小进行了估算。冰雹探测算法输出三个产品:任何尺寸冰雹概率(POH)强冰雹概率(POSH)冰雹尺寸大小(MEHS)。
1.1 一维风暴段(SEGMENT)的形成定位三维风暴单体是从一维风暴段开始的。一个风暴段定义为一段连续的沿着一个径向的一系列距离库,他们的反射率因子超过一个规定的阈值(记为REFLECTIVITY)当处理过程沿一个雷达径向首次遇到一个大于规定的阈值的反射率因子时,随后的超过阈值的距离库被编为一组,一直到遇到一个小于阈值的距离库。如果该距离库的反射率因子值与阈值的差值小于5dBz (记为DROPOUT REF DIFF, 是可调参数),或这样的距离库小于2个(记为DROP OUT COUNT, 是一个可调参数),则过程继续。如果算法遇到的距离库的反射率因子值小于上述反射率因子阈值REFLECTIVI TY 5dBz以上或小于REFLECTIVITY的距离库超过或等于两个,则过程终止,一个风暴段就此产生。如果风暴段的径向长度超过SEGMENT LENGTH (—个可调参数,缺省值为1.9km)它将被储存下来。
为了取得更好的风暴定位效果,一般用多个反射率阈值(REFLECTIVTY1-7 (60,55,50,45,40,35,30))来生成不同的段。
1.2 二维风暴分量(COMPONENT)组合对每层的反射率数据取得每个径向的段以后,就可以对相邻径向的段进行合并,得到不同的风暴分量(COMPONENT)。一个二维风暴分量必须满足下面的条件:1)相邻风暴段的重叠距离必须大于风暴重叠距离阈值(SEGMENT OVERLAP RANGE=1.95km); 2)相邻风暴段的方位角的间距必须小于方位角的间距阈值(AZI-M UTHAL SEPERATION=1.5°); 3)组成风暴分量的段的个数必须大于段个数阈值(SEGMENT LENGTH=2);4)组成风暴分量的面积满足面积阈值(AREA=10km)。对于所有反射率阈值构成的二维分量,计算它们的位置。如果反射率阈值大的风暴分量中心落在反射率阈值小的风暴分量中心,则把反射率阈值小的风暴分量剔除。最后所有阈值的二维风暴分量按照风暴分量的质量从大到小排序。
1.3 三維立体风暴(STCRM)的生成每一层的二维风暴分量(COMPO NENT)都搜索完成以后,从最低层开始对相邻仰角的二维风暴分量进行垂直组合。这里引入了三个搜索半径阈值(SEARCH RADIUS=5.0,7.5,10km)。步骤如下:首先,如果相邻层次的两个风暴分量的中心水平距离在搜索半径阈值以内,则认为它们相关(一个风暴分量可能和上一层的多个风暴分量相关,但由于二维风暴分量是按照风暴的质量排序的,所以,最大的质量的风暴分量首先相关),一个立体风暴被创建。其次,如果当前的搜索半径没有找到相关的二维风暴分量,则扩大搜索半径,直到找到为止或己经达到最大的搜索半径。有时候,一个风暴可能被识别成靠得很近的几个小风暴。如果两个风暴满足如下几个条件,则它们被合并成一个风暴:1)两个风暴没有同一个仰角的二维风暴分量; 2)两个风暴的中心距离不大于风暴水平合并阈值(HOR IZONTALMERGE=10.0km); 3)两个风暴的其中一个风暴顶和另一个风暴底的垂直距离和仰角差值满足规定的垂直距离阈值(HEIGHT MERGE=4.0km)和仰角差阈值(ELEVATION MERGE=3.0°)。最后,为了防止风暴过于拥挤,如果两个风暴在水平方向上靠得很近,并且风暴的高度差满足一定的阈值,则液态含水量比较小的风暴被删除。
1.4 任何尺寸冰雹概率(POH)的计算得到风暴的定位信息以后,根据风暴45dBz反射率的高度和0 ℃层的高度差经验关系,得出POH, 经验关系如图 1。

|
图 1 45dBz反射率高度和0℃层高度差与冰雹概率(POH)的关系 |
强冰雹主要是指冰雹尺度大于20mm的冰雹。考虑了温度和反射率因子大小的因素,首先引入了强冰雹指数(SHI)的概念,定义为
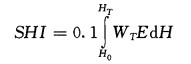
|
其中SHI为大冰雹指数,WT为权重函数,E为冰雹动能。H0为溶化层高度,HT为风暴单体顶高。E的表达式为:
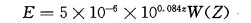
|
权重函数W(Z)被用来定义雨和冰雹反射率因子的转换区,它的值介于0~1之间。权重函数WT为大气温度层结的权重函数,它的值介于0~1之间。最后得到的SHI的单位是J·m-1·s-1。
在得到SHI以后,需要确定一个报警阈值WT(WARING THRESHOLD)来得到强冰雹的概率。这里采用WSR-88D的经验公式,WT的单位为J·m-1·s-1。
最后,根据WSR-88D的经验公式,形成POSH的公式为:
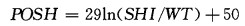
|
POSH就是强冰雹概率。它的值介于0~100%之间,当WT=SHI时概率为50%。
1.6 冰雹尺寸(MEHS)的计算在得到冰雹指数以后,根据如下的经验公式:
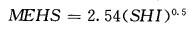
|
可以得到冰雹的大小,MEHS的单位为毫米。
2 应用分析根据上述算法,采用VISUAL C ++ 6.0编程语言,设计了一套基于雷达基数据的软件,用它来实时对冰雹进行定位和识别。该软件不仅提供了图形产品,还提供了冰雹各层的风暴信息结构。
考虑到冰雹的实况信息收集的不一定很完全,只采用了16个有冰雹大小实况报告的个例进行了分析。首先,和METSTAR公司10.8版本冰雹探测结果比较如表 1。
|
|
表 1 和METSTAR10.8版本探测结果大小和误差分析 |
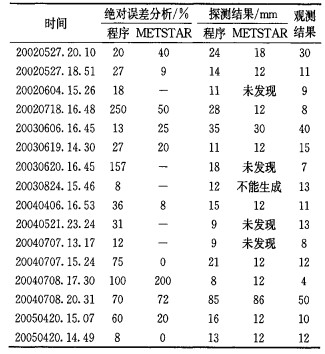
从表 1可以看出:
(1) 两者的平均误差分别为57% (本程序)和40% (METSTAR), 说明二者的探测能力相当。
(2) METSTAR公司的软件探测距离为230km以内,造成有些冰雹未能探测出来。
其次,和METSTA R7.0版本探测结果进行比较,由于7.0版本输出没有冰雹大小,采用评分方法比较。定义POD/FAR/CSI (探测概率/误报率/临界成功指数)如下:
|
|
表 2 POD、FAR、CSI的定义 |

其中:
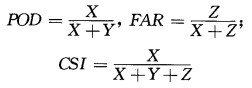
|
得出的评分结果如表 3。
|
|
表 3 和METSTAR7.0版本探测结果评分比较 |
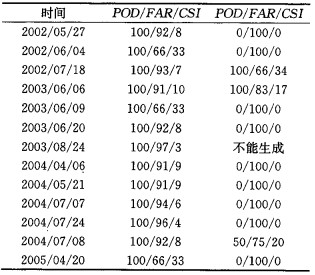
结果表明,新的算法比旧的算法探测效果有量级上的提高。
在冰雹算法中,0℃/-20 ℃的高度是一个比较重要的参数。这个高度有时会变化很大。在研究中我们发现,输入当天准确的0℃/-20℃度高度,对冰雹大小的探测有比较好的效果,如表 4所示。
|
|
表 4 0℃/-20℃高度改变结果 |

从表 3可以看出,冰雹探测结果误报率过高。我们尝试提高冰雹探测的反射率阈值,将原来的45dBz提高到50dBz。使得误报率有一些降低。总体效果(CSI)有一些改善,如表 5。
|
|
表 5 提高冰雹探测反射率阈值评分效果 |

结论:除了两个个例的CSI有所下降(因为有两个冰雹未能探测出来),其它个例的CSI都有一定程度的提高,误报率降低比较明显。
4 小结(1) 从探测效果比较,程序对冰雹探测的效果和METSTAR10.8版相当,比METSTAR7.1版探测效果好。
(2) 输入当天实际的0℃/-20℃高度值有利于冰雹探测的效果。
(3) 适当提高冰雹探测的临界反射率值,对冰雹的探测效果有一些改善。
由于缺少地面实际冰雹观测数据,估计冰雹概率POH的性能比较困难。并且,强冰雹概率和冰雹大小的公式是参照美国WSR-88D的经验公式。今后,随着冰雹探测个例的増加,需要进一步研究适合于本地情况的相关经验公式及参数,以便提高冰雹探测的效果。
| [1] |
俞小鼎. 新一代天气雷达对局地强风暴预警的改善[J]. 气象, 2005, 30(8): 3-7. |
| [2] |
Johnson J.T., MacKeen P.L., Witt A. The stoim cell identification and tracking algorithm:an enhanced WSR-88D algorithm[J]. Wea. Forecating, 1998, 13: 263-276. |
| [3] |
杨引明. WSR-88D多普勒天气雷达冰雹探测算法及评价[J]. 气象, 2002, 25(5): 39-43. |